ARTICLE
Components of an Orchestrator
From Build an Orchestrator in Go by Tim Boring
This article covers
- The evolution of application deployments
- Classifying the components of an orchestration system
Take 35% off Build an Orchestrator in Go by entering fccboring into the discount code box at checkout at manning.com.
Introduction
Kubernetes. Kubernetes. Kubernetes. If you’ve worked in or near the tech industry in the last five years, you’ve at least heard the name. Perhaps you’ve used it in your day job. In this article, we’re going to see what it takes to build our own Kubernetes; write the code to gain a better understanding about what Kubernetes is. And what Kubernetes is, in the general sense, is an orchestrator.
The (Not So) Good ‘Ole Days
Let’s take a journey back to 2002 and meet Michelle. Michelle is a system administrator for her company, and she is responsible for keeping her company’s applications up and running around the clock. How does she accomplish this?
Like many other sysadmins, Michelle employs the common strategy of deploying applications on bare metal servers. A simplistic sketch of Michelle’s world can be seen in Figure 1. Each application typically runs on its own physical hardware. To make matters more complicated, each application has its own hardware requirements, and Michelle has to buy and then manage a server fleet which is unique to each application. Moreover, each application has its own unique deployment process and tooling. The database team gets new versions and updates via CD, and its process involves a database administrator (DBA) copying files from the CD to a central server, then using a set of custom shell scripts to push the files to the database servers, where another set of shell scripts handles installation and updates. Michelle handles the installation and updates of the company’s financial system herself. This process involves downloading the software from the Internet, at least saving her the hassle of dealing with CDs, but the financial software comes with its own set of tools for installing and managing updates. Several other teams are building the company’s software product, and the applications that these teams build have a completely different set of tools and procedures.

If you weren’t working in the industry during this time and didn’t experience anything like Michelle’s world, consider yourself lucky. Not only was that world chaotic and difficult to manage, it was also extremely wasteful. Virtualization came along next in the early to mid-aughts. These tools allowed sysadmins like Michelle to carve up their physical fleets to allow each physical machine to host several smaller yet independent virtual machines (VMs). Instead of each application running on its own dedicated physical machine, it now ran on a VM. And multiple VMs could be packed onto a single physical one. Although virtualization made life for folks like Michelle better, it wasn’t a silver bullet.
This was the way until the mid-2010s when two new technologies appeared on the horizon. The first was Docker, which introduced containers, a lighter weight virtualization technology that allowed running containers to share the OS. The second new technology to appear at this time was Kubernetes, an orchestration system focused on automating the deployment and management of containers.
What is an orchestrator?
Before diving in head first and writing code, let’s define the term orchestrator. An orchestrator is a system that provides automation for deploying, scaling, and otherwise managing containers. In such systems, applications no longer run “naked” on bare metal or virtualized machines. Instead, they run inside containers. Table 1 summarizes the different features of each of the deployment and management models we’ve touched on.
Comparison of the three major deployment and management models used in the last twenty years.

The components of an orchestration system
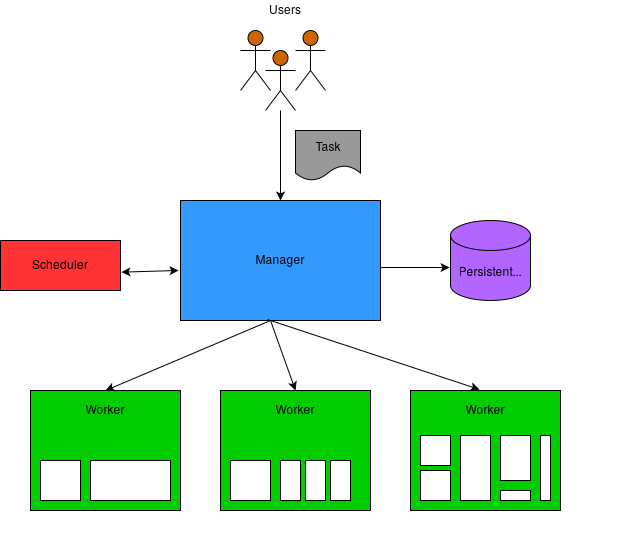
An orchestrator automates deploying, scaling, managing containers. Next, let’s identify the components and their requirements that make those features possible. These components can be seen in Figure 2. They are:
- The task
- The job
- The scheduler
- The manager
- The worker
- The cluster
- The CLI
The Task
The task is the smallest unit of work in an orchestration system and typically runs in a container. You can think of it like a process that runs on a single machine. A single task could run an instance of a reverse proxy like Nginx; or it could run an instance of an application like a RESTful API server; it could be a simple program that runs in an endless loop and does something silly, like ping a website and write the result to a database.
A task should specify the following:
- The amount of memory, CPU, and disk it needs to run effectively
- What the orchestrator should do in case of failures, often called restart_policy
- The name of the container image used to run the task
Task definitions may specify additional details, but these are the core requirements.
The Job
The job is an aggregation of tasks. It has one or more tasks that typically form a larger logical grouping of tasks to perform a set of functions. For example, a job could be comprised of a RESTful API server and a reverse proxy.
A job should specify details at a higher level than tasks:
- Each task that makes up the job
- Which data centers the job should run in
- The type of the job
We won’t be dealing with jobs in our implementation, for the sake of simplicity.
The Scheduler
The scheduler decides what machine can best host the tasks defined in the job. It can be run as an independent process within the manager or as a completely separate service. The decision-making process can be as simple as selecting a node from a set of machine in a round-robin fashion, or as complex as calculating a score based upon a number of variables and selecting the node with the “best” score.
The scheduler should perform these functions:
- Determine a set of candidate machines on which a task could run.
- Score the candidate machines from best to worst.
- Pick the machine with the best score.
The Manager
The manager is the brain of an orchestrator and the main entry point for users. In order to run jobs in the orchestration system, users submit their jobs to the manager. The manager, using the scheduler, then finds a machine where the job’s tasks can run. The manager also periodically collects metrics from each of its workers, which are used in the scheduling process.
The manager should do the following:
- Accept requests from users to start and stop tasks.
- Schedule tasks onto worker machines.
- Keep track of tasks, their states, and the machine on which they run.
The Worker
The worker provides the brawns of an orchestrator. It’s responsible for running the tasks assigned to it by the manager. If a task fails for any reason, it must attempt to restart the task. The worker also makes metrics about its tasks and its overall machine health available for the master to poll.
The worker is responsible for the following:
- Running tasks as Docker containers.
- Accepting tasks to run from a manager.
- Providing relevant statistics to the manager for the purpose of scheduling tasks.
- Keeping track of its tasks and their state.
The Cluster
The cluster is the logical grouping of all the above components. An orchestration cluster could be run from a single physical or virtual machine. More commonly a cluster is built from multiple machines, from as few five to as many as thousands or more.
CLI
Finally, our CLI, the main user interface, should allow a user to:
- Start and stop tasks
- Get the status of tasks
- See the state of machines (i.e. the workers)
- Start the manager
- Start the worker
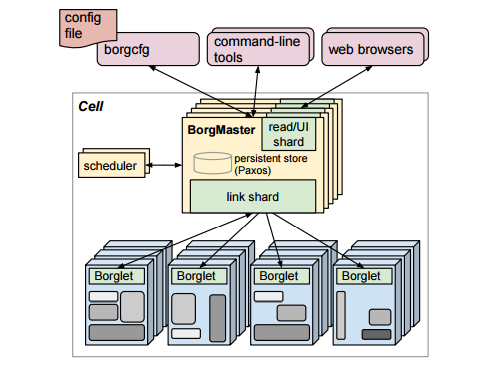
All orchestration systems share these same basic components. Google’s Borg, seen in Figure 3, calls the manager the BorgMaster and the worker a Borglet, but otherwise uses the same terms as defined above.
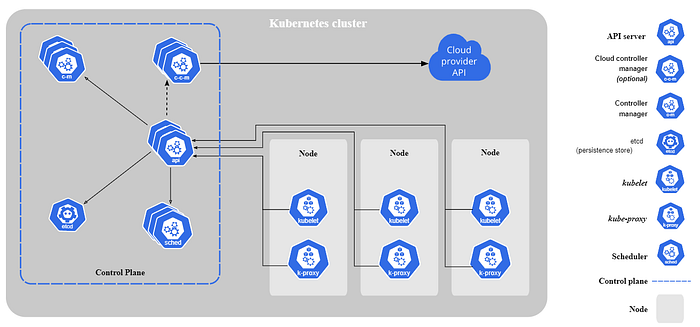
Kubernetes, which was created at Google and influenced by Borg, calls the manager the control plane and the worker a kubelet. It rolls up the concepts of job and task into Kubernetes objects. Finally, Kubernetes maintains the usage of the terms scheduler and cluster. These components can be seen in the Kubernetes architecture diagram in Figure 4.
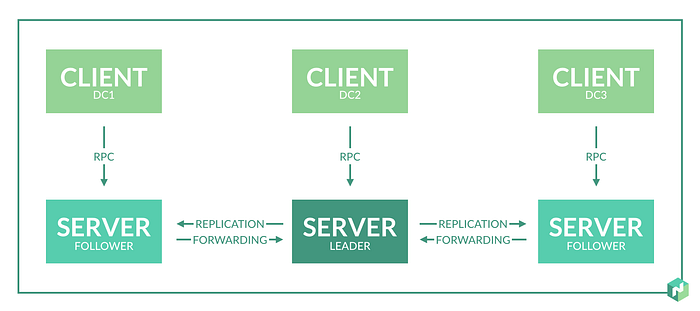
Hashicorp’s Nomad, seen in Figure 5, uses more basic terms. The manager is the server, and the worker is the client. Although not shown in the figure, Nomad uses the terms scheduler, job, task, and cluster as we’ve defined here.
Why implement an orchestrator from scratch?
If orchestrators such as Kubernetes and Nomad already exist, why write one from scratch? Couldn’t we look at the source code for them and get the same benefit?
Perhaps. Keep in mind, though, Kubernetes and Nomad are large software projects. Both contain more than two million lines of source code. Although not impossible, learning a system by slogging around in two million lines of code may not be the best way.
Instead, we’re going to roll up our sleeves and get our hands dirty.
To ensure we focus on the core bits of an orchestrator and don’t get sidetracked, we’ll narrow the scope of our implementation. The orchestrator you write in the course of the book is fully functional. You can start and stop jobs, and interact with those jobs. It won’t be production ready. After all, our purpose isn’t to implement a system that replaces Kubernetes or Nomad. Instead, our purpose is to implement a minimal system that gives us deeper insight into how production-grade systems like Kubernetes and Nomad work.
Now you’ve seen what it takes to build your own Kubernetes. If you want to learn more, check out the book on Manning’s liveBook platform here.
