ARTICLE
More Sensitive Suggestions
From Deep Learning for Search by Tommaso Teofili
__________________________________________________________________
Save 37% off Deep Learning for Search. Just enter fccteofili into the discount code box at checkout at manning.com.
__________________________________________________________________
This article discusses how neural networks can help generate text that a human might write in order to provide more sensitive suggestions and enhance autocomplete functionality.
It’s common for search engines to provide a “suggestion” or “autocomplete” functionality, which aids users while typing queries to speed up the querying process, while suggesting words or sentences which would make up a meaningful query. If a user starts typing “boo”, the autocomplete feature may provide the rest of the word the user is likely to be writing: “book,” or a complete sentence which starts with “boo” like “books about deep learning.” Although helping users compose their queries is good to avoid typos and similar errors, this autocomplete functionality gives the search engine the opportunity to “hint” words or sentences that make more sense in the context of the query the user is writing. Therefore it also has an impact on the effectiveness of the search engine. Interestingly the search engine has a chance here to favor certain suggestions over others, for example for marketing purposes.
Because autocomplete is a common feature in search engines, there are already algorithms that can accomplish this task. So, what can neural networks help us with? Neural networks can learn to generate text which looks like it was written by a human. In this article we’ll use and extend such neural nets and see how they outperform the currently most widely-used algorithms for autocompletion and generating sensitive suggestions.
Suggesting while composing queries
Consider the case of how to help users of a search engine look for song lyrics, in the common scenario in which one doesn’t exactly recall a song title. In this context, the synonym expansion technique allows users to fire a possibly incomplete or incorrect query (e.g. music is my aircraft), to get it fixed by expanding synonyms under the hood (music is my aeroplane) using the word2vec algorithm. Synonym expansion is a useful technique, but maybe we could have done something simpler to help a user recall that the song chorus reads music is my *aeroplane* and not music is my aircraft, by suggesting the right words while the user was typing the query. Instead, we let the user run a suboptimal query — in the sense that the user already knew aircraft wasn’t the right word. Having good auto completion algorithms has two benefits
- less queries with few / zero results (affects recall)
- less queries with low relevance (affects precision)
In fact, if the suggester algorithm is “good” it won’t output non-existing words or terms which never occurred in the indexed data. This means it’s unlikely that a query using terms suggested by such algorithm will return no results. Additionally, let’s think about the music is my aircraft example. Provided we don’t have synonym expansion enabled, there’s probably no song which contains all such terms and therefore the “best” results will contain music and my or my and aircraft, with low relevance to the user information need (and hence low score).
Ideally once we get to write music is my… the suggester algorithm will hint us with aeroplane, because this is, for example, a sentence that the search engine has already seen (indexed). We just touched an important point which plays a key role in having effective suggestions: where can suggestions come from? Most commonly they originate from:
- static (hand crafted) dictionaries of words or sentences to be used for suggestions
- chronology of previously entered queries (e.g. taken from a query log)
- indexed documents as terms for suggestions are taken from possibly different portions of the documents (title, main text content, authors, etc.)
In the rest of this article we’ll have a look at tapping suggestions from the above sources by using common techniques from the fields of information retrieval and natural language processing. We’ll also see how they compare with suggesters based on neural network language models, a long standing NLP technique, but implemented through neural networks in terms of features and accuracy of results.
Dictionary-based suggesters
Back in the “old days” when search engines required a lot of hand-crafted algorithms, a common approach was to build a dictionary of words that could be used to help users type queries. Such dictionaries usually contained important words only, like main concepts that were closely related to that specific domain. For example, a search engine for a musical instrument shop may have used a dictionary containing things like guitar, bass, drums, piano, etc. In fact it would have been difficult to fill the dictionary, for example, with all the English words by compiling it by hand. It’s possible instead to have such dictionaries build “themselves” (e.g. using some script) by looking into the query logs, geting the user entered queries, and extracting a list of the 1000 (for example) most frequent terms. That way we can avoid having misspelled words making it into the dictionary, by means of the frequency threshold (hopefully people type queries without typos most of the time…). Given the above scenario, dictionaries can still be a good resource for query history based suggestions — you can either use that data to suggest exactly the same queries or portions of them.
Let’s take the opportunity to build a dictionary-based suggester using Lucene APIs and terms from previous query history. In the following section we’ll be implementing this same API using different sources and suggestion algorithms; this helps us compare them in order to evaluate which one to choose depending on the use case.
Lucene Lookup APIs
Suggest/autocompletion features are provided by means of the Lookup API in Apache Lucene . The lifecycle of a Lookup usually includes:
- build phase: where the Lookup is built from a certain data source (e.g. a dictionary)
- lookup phase: where the Lookup is used to provide suggestions based on a sequence of characters (and some other, optional, parameters)
- rebuild phase: in case the data to be used for suggestion gets updated or a new source needs to be used
- store/load phase: where Lookups are persisted (e.g. for future reuse) and loaded (e.g. from a previously saved lookup or a disk)
Let’s now build our first Lookup using a dictionary, in particular we’ll use a file containing the 1000 previously entered queries as they were recorded in the search engine log. Our queries.txt file will look like this, one query per line:
...
popular quizzes
music downloads
music lyrics
outerspace bedroom
high school musical sound track
listen to high school musical soundtrack
...We’ll now build a Dictionary from this plain text file and pass it to the Lookup to build our first dictionary-based suggester.
Lookup lookup = new JaspellLookup(); ❶
Path path = Paths.get("queries.txt"); ❷ Dictionary dictionary = new PlainTextDictionary(path); ❸ lookup.build(dictionary); ❹❶ instantiate a Lookup
❷ locate the input file containing the queries (one per line)
❸ create a plain text dictionary which reads from the queries file
❹ build the Lookup using the Dictionary
implementation called JaspellLookup, which is based on a ternary search tree, is fed with data coming from a dictionary containing past queries. A ternary search tree (or TST) is a data structure where Strings are stored in a way that recalls the shape of a tree, in particular a TST is a particular type of tree called a prefix tree (or trie) where each node in the tree represents a character and has a maximum three child nodes. Such data structures are particularly useful for autocompletion because they’re efficient in terms of speed when searching for Strings that have a certain prefix, which is why prefix trees are used in the context of autocompletion, because as you search for “mu” the trie can give you all the Strings in that start with “mu” efficiently.
Now that we’ve built our first suggester, let’s see it in action. Think back to the query “music is my aircraft” when we mentioned synonym expansion. We’ll split that query into bigger sequences and pass them to the lookup to get suggestions, simulating the way users type queries in a search engine user interface. We’ll start with “m”, then “mu,” “mus,” “musi,” and so on, and see what kind of results we get from our Lookup based on past queries. We generate such “incremental inputs” by using the code below:
List<String> inputs = new LinkedList<>();
for (int i = 1; i < input.length(); i++) {
inputs.add(input.substring(0, i)); ❶
}❶ at each step we create a substring of the original input where the ending index i is bigger
Lucene’s Lookup#lookup API accepts a sequence of characters (the input of the user typing the query) and a few other parameters, like if we only want the “more popular” suggestions (e.g. more frequent Strings in the dictionary) and the maximum number of such suggestions to retrieve. Using the above List of incremental inputs, we’ll generate the suggestions for each such substring.
List<Lookup.LookupResult> lookupResults = lookup.lookup(substring, false, 2); ❶❶ we use the Lookup to obtain maximum 3 results for a given substring (e.g. “mu”), regardless of their frequency (morePopular parameter is set to false)
We obtain a List of LookupResults, each such result is composed by a key which is the suggested String and a value which is the weight of that suggestion, and such weight can be thought of as a measure of how relevant/frequent the suggester implementation thinks the related String is, and its value may vary depending on the Lookup implementation used. We’ll show each suggestion result together with its weight:
for (Lookup.LookupResult result : lookupResults) {
System.out.println("--> " + result.key + "(" + result.value + ")");
}If we pass all the generated substrings of “music is my aircraft” to our suggester we’ll get:
'm'
--> m(1)
--> m &(1)
----
'mu'
--> mu(1)
--> mu alumni events(1)
----
'mus'
--> musak(1)
--> musc(1)
----
'musi'
--> musi(1)
--> musi for wish you could see me now(1)
----
'music'
--> music(1)
--> music &dvd whereeaglesdare(1)
----
'music '
--> music &dvd whereeaglesdare(1)
--> music - mfs curtains up(1)
----
'music i'
--> music i can download for free no credit cards and music parental advisary(1)
--> music in atlanta(1)
----
'music is'
----
... ❶❶ no more suggestions
As you can see, we get no more suggestions for inputs beyond “music i.” Not too good. The reason for this is that we’ve built a Lookup solely based on entire query strings, and we didn’t provide any means for the suggester to split such text lines into smaller text units. Therefore, the Lookup wasn’t able to suggest ‘is’ after ‘music’ because no previously entered query started with “music is…” This is a strong limitation. On the other hand, this kind of suggestion is handy for “chronological only” autocompletion, and a user starts seeing previous queries he or she entered in the past as soon as he or she starts typing a new one. This isn’t bad per se and can already be a good boost for user experience in terms of speed. In fact, if such a user wants to run exactly the same query they fired off a week before, it would show up by using the above described Lookup implementation based on a Dictionary of previously entered queries. We, however, want to do more:
- we want to be able to suggest not only entire strings that the user typed in the past, but also single words, e.g. those that composed past queries (music, is, my, aircraft)
- even with entire query strings, we’d like to be able to suggest such strings even if the user starts typing a word that stands in the middle of a previously entered query. Think again to “music is my aircraft.” The method shown above gives results if the query string starts with what user is typing, but we’d like to be able to suggest “music is my aircraft” even if the user types “my a”
- we’d like to also suggest unseen word sequences, and the suggest functionality should be able to compose natural language to help users write better-sounding queries
- we’d like suggestions to reflect the data from the search engine. It’d be extremely frustrating for a user if the suggestions lead to an empty list of results
- help users disambiguate when a query may have different scopes among the possible interpretations. Imagine a query like “neuron connectivity,” which could relate to the field of neuroscience as well as to artificial neural networks. It’d be helpful if we could give a hint to the user that such a query may possibly hit different domains, and let him filter the results before firing the query
Let’s work more on each of these points and see how the usage of neural networks allows us to achieve more accurate suggestions when compared to other techniques.
Analyzed suggesters
Think about typing a query on a web search engine: in many cases you don’t know upfront the whole query you’re going to write. This might have not been true years ago when most of web searching was based on keywords, and people had to think in advance: “what are the most important words I have to look for in order to get search results that are relevant?” That way of searching was also a lot more of a “trial and error” process than it is today. One thing this has influenced it is that good web search engines give good hints while you are typing a query, whereby you type, look at the suggestions, select one, then start typing again and look for additional suggestions, select another suggestion, etc. Let’s run a simple experiment and look at the suggestions we get when searching for “books about search and deep learning” on Google.
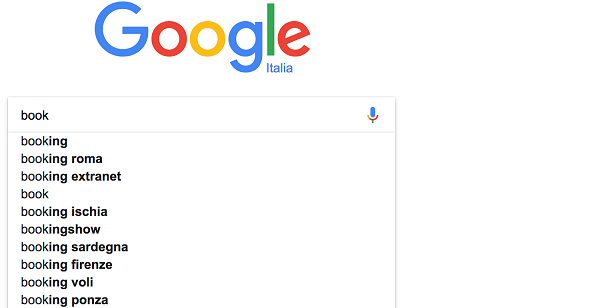
As we type “book” the results are generic (as we may expect, because ‘book’ can have a lot of different meanings in different contexts), and we get suggestions about bookings for going on vacation in Italy (Roma, Ischia, Sardegna, Firenze, Ponza). At this stage suggestions don’t seem different in shape from what we created with our dictionary-based suggester with Lucene in the previous section: all suggestions start with book. We aren’t selecting any suggestions because none are relevant for our intents and we keep typing “books about sear”:
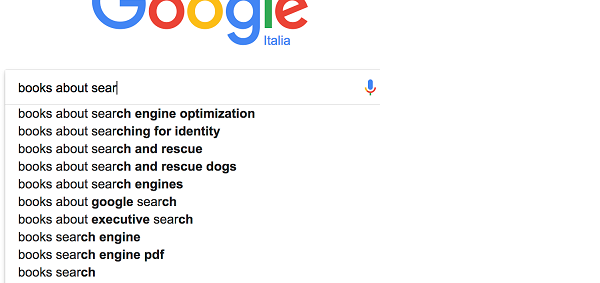
The suggestions are starting to become more meaningful and closer to our search intent, though the first results are not relevant (books about search engine optimization, books about searching for identity, and books about search and rescue). The fifth suggestion is probably the closest. It’s interesting to note that we also got:
- an infix suggestion (a suggestion string that contains a new token-placed infix between two existing tokens of the original string). Let’s look at the “books about google search” suggestion, the word google stands between about and sear in the query we typed, let’s keep this in mind as this is something we’ll want to achieve, but for now we’ll skip it is as we’re not interested in “google search” results.
- a suggestion which skipped the word about (the last three ones, books search…). Let’s also keep this in mind, we can discard some terms from the query while giving suggestions
We select “books about search engines” suggestion and start typing “and,” getting the results below:
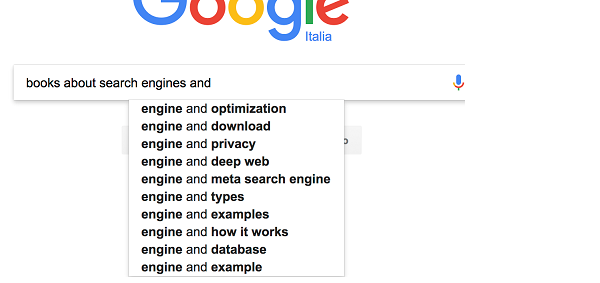
If we look at the results we probably realize the topic of integration of search engines and deep learning doesn’t have much book coverage, as none of the suggestions offer “deep learning.” A more important thing to note is that it seems the suggester has discarded some of the query text to give us hints; if you look at the suggestions box, the results all start with “engine and,” but this might only be a user interface thing because the suggestions seem to be accurate; they’re not about “engines” in general, they clearly reflect the fact that engine here is a search engine. Anyway this also gives us another hint, we may want to discard some of the query text as they become longer. For the sake of our information need, let’s keep typing:
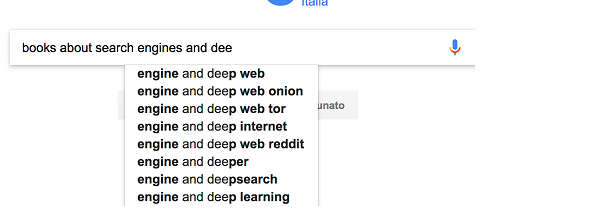
The final suggestion makes up for the query we had in mind, with a small modification: we had “books about search and deep learning” in mind while we came out with “books about search engines and deep learning.”
In this experiment we didn’t want to learn how Google search engine implements autocompletion, but it was useful to do some observations, reason it out, and decide what’s useful in practice for our own search engine applications. We observed that some suggestions had:
- some words were removed (books about search engines)
- some infix suggestions were inserted (books about google search)
- some prefixes were possibly removed (books about seemed to be omitted in the last suggestions)
All this, and much more, is possible by applying text analysis to the incoming query and the data from the dictionary we use to build our suggester. We can, for example, remove certain terms by using a stop word filter. Or we can break long queries into multiple subsequences, and generate suggestions for each subsequence by using a filter that breaks a text stream at a certain length. This fits nicely with the fact that text analysis is heavily used within search engines. Lucene has such a Lookup implementation, called AnalyzingSuggester. Instead of relying on a fixed data structure, it uses text analysis to let us define what we expect to be done — first during Lookup build and second when passing a piece of text to the Lookup to get suggestions.
Analyzer buildTimeAnalyzer = new StandardAnalyzer(); ❶ Analyzer suggestTimeAnalyzer = new StandardAnalyzer(); ❷ Directory dir = FSDirectory.open(Paths.get("suggestDirectory")); ❸ AnalyzingSuggester lookup = new AnalyzingSuggester(dir, "prefix",
buildTimeAnalyzer suggestTimeAnalyzer); ❹❶ when we build the Lookup we use a StandardAnalyzer which removes stopwords and split tokens on whitespace
❷ when we look for suggestions we use the same analyzer used at build time
❸ we need a Directory because the Analazying suggester uses it internally to create the required data structures for generating suggestions
❹ create an AnalyzingSuggester instance
The AnalyzingSuggester can be created using separate Analyzers for build and lookup times, and this allows us to be creative when setting up the suggester. Internally this Lookup implementation uses a finite state transducer, a data structure used in several places in Lucene.
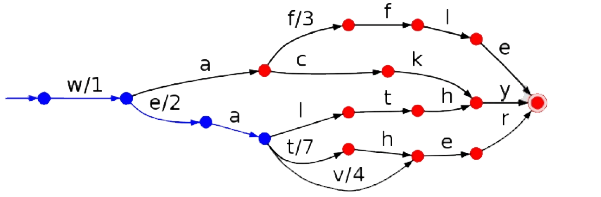
You can think to a finite state transducer as a graph in which each edge is associated with a character and optionally a weight. At build time, all possible suggestions coming from applying the build time Analyzer to the dictionary entries are compiled into a big FST. At query time, traversing the FST with the (analyzed) input query will produce all the possible paths and, consequently, suggestion strings to output. Let’s see what it can do with respect to the one based on the ternary search tree.
'm'
--> m(1)
--> .m(1)
----
'mu'
--> mu(1)
--> mu'(1)
----
'mus'
--> musak(1)
--> musc(1)
----
'musi'
--> musi(1)
--> musi for wish you could see me now(1)
----
'music'
--> music(1)
--> music'(1)
----
'music '
--> music'(1)
--> music by the the(1)
----
'music i'
--> music i can download for free no credit cards and music parental advisary(1)
--> music industry careers(1)
----
'music is'
--> music'(1)
--> music by the the(1)
----
'music is '
--> music'(1)
--> music by the the(1)
----
'music is m'
--> music by mack taunton(1)
--> music that matters(1)
----
'music is my'
--> music of my heart by nicole c mullen(1)
--> music in my life by bette midler(1)
----
'music is my '
--> music of my heart by nicole c mullen(1)
--> music in my life by bette midler(1)
----
'music is my a'
--> music of my heart by nicole c mullen(1)
--> music in my life by bette midler(1)
----
'music is my ai'
----
... ❶❶ no more suggestions
The previous ternary search tree based suggester stopped providing suggestions beyond ‘music i’ as no entry in the dictionary started with ‘music is.’ We can see that with this analyzed version even though the dictionary is the same, it keeps suggestions coming until there’s at least one matching token suggestion. In the case of ‘music is,’ the token ‘music’ matches some suggestions and therefore the related results are provided, even though ‘is’ doesn’t add any suggestions. Even more interestingly, as the query becomes ‘music is my,’ there are some suggestions which contain both ‘music’ and ‘my.’ At a certain point, where there’re too many tokens that don’t match the Lookup stops providing suggestions as they might be too poorly related to the given query (starting with ‘music is my ai’). This is already a good advance over the previous implementation and solves one of the mentioned problems: we can also provide suggestions based on single tokens, not only on entire strings. We can also enhance things a bit by using a slightly modified version of AnalyzedSuggester which works better with “infix” suggestions.
AnalyzingInfixSuggester lookup = new AnalyzingInfixSuggester(dir, buildTimeAnalyzer, lookupTimeAnalyzer, ... );By using this infix suggester we get fancier results:
'm'
--> 2007 s550 mercedes(1)
--> 2007 qualifying times for the boston marathon(1)
----
'mu'
--> 2007 nissan murano(1)
--> 2007 mustang rims com(1)
----
'mus'
--> 2007 mustang rims com(1)
--> 2007 mustang(1)We don’t get results starting with ‘m,’ ‘mu,’ or ‘mus,’ instead such sequences seem to be used to match the most important part of a String, like ‘2007 s550 Mercedes,‘ ‘2007 qualifying times for the Boston marathon,‘ ‘2007 Nissan Murano,‘ ‘2007 Mustang rims com.’ Another noticeable difference is that token matching can happen in between a suggestion, this is why it’s called an infix:
'music is my'
--> 1990's music for myspace(1)
--> words to music my humps(1)
----
'music is my '
--> words to music my humps(1)
--> where can i upload my music(1)
----
'music is my a'
--> words to music my humps(1)
--> where can i upload my music(1)
----With the AnalyzingInfixSuggester we managed to get infix suggestions. In fact it takes the input sequence, analyzes it to create tokens, and then suggests matches based on prefix matches of any such tokens. We still have the problem of making suggestions closer to the data stored in the search engine, and making suggestions look more like natural language that are able to better disambiguate when two words have different meanings.
Neural language models
A neural language model is supposed to have the same capabilities of other types of language models, such as the ngram models. The difference lies in how they learn to predict probabilities and how much better their predictions are. RNNs are also very good at learning sequences of text in an unsupervised way, in order to generate new good-sounding sequences based on previously seen ones. A language model learns to get accurate probabilities for word sequences, so this looks like a perfect fit for recurrent neural networks. Let’s start with a simple non-deep recurrent neural network implementing a character level language model, so that the model will predict the probabilities of all the possible output characters, given a sequence of input characters.
Let’s visualize it:
LanguageModel lm = ...
for (char c : chars) {
System.out.println("mus" + c + ":" + lm.getProbs("mus"+c));
} .... musa:0.01
musb:0.003
musc:0.02
musd:0.005
muse:0.02
musf:0.001
musg:0.0005
mush:...
musi:...
...
We know that a neural network uses vectors for inputs and outputs, the output layer of the RNN we used for text generation in chapter 3 produced a vector holding a real number (between 0 and 1) for each possible character to output, such a number will represent the probability of such a character to be outputted from the network. We’ve also seen that this task of generating probability distributions (the probability for all the possible characters, in this case) is accomplished by the SoftMax function. Now that we know what the output layer does, we put a recurrent layer in the middle, which is responsible for keeping previously observed sequences in its memory, and an input layer for sending input characters to our network. This will result in the following diagram:

With DL4J we already configured such a network in the following way:
int layerSize = 50; ❶
int sequenceSize = chars.length(); ❷
int unrollSize = 100 ❸
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .layer(0, new LSTM.Builder().nIn(sequenceSize).nOut(layerSize).activation(Activation.TANH).build()) .layer(1, new
RnnOutputLayer.Builder(LossFunction.MCXENT).activation(Activation.SOFTMAX).nIn(layerSize).nOut(sequenceSize).build())
.backpropType(BackpropType.TruncatedBPTT).tBPTTForwardLength(unrollSize).tBPTTBackwardLength(unrollSize)
.build();❶ the size of the hidden layer
❷ the input and output size
❸ the number of “unrolls” of the RNN
While the fundamental architecture is the same (LSTM network with 1 or more hidden layers), our goal here is different with respect to what we wanted to achieve in chapter 3 (alternative query generation). In fact, we need the RNN to guess good completions for the query the user is writing before they’re finished typing it.
Character-based neural language model for suggestions
Since the plan is to use the neural network as a tool to help the search engine, the data to feed it should come from the search engine itself. Let’s index the Hot 100 Billboard dataset:
IndexWriter writer = new IndexWriter(directory, new IndexWriterConfig()); ❶ for (String line : IOUtils.readLines(getClass().getResourceAsStream("/billboard_lyrics_1964-2015.csv"))) { ❷
if (!line.startsWith("\"R")) { ❸
String[] fields = line.split(","); ❹
Document doc = new Document();
doc.add(new TextField("rank", fields[0], Field.Store.YES)); ❺
doc.add(new TextField("song", fields[1], Field.Store.YES)); ❻
doc.add(new TextField("artist", fields[2], Field.Store.YES)); ❼
doc.add(new TextField("lyrics", fields[4], Field.Store.YES)); ❽
writer.addDocument(doc); ❾
}
}
writer.commit(); ❿
❶ create an IndexWriter to put documents into the index
❷ read each line of the dataset, one at a time
❸ do not use the “header” line
❹ each row in the file has the following attributes, separated by a comma: Rank, Song, Artist, Year, Lyrics, Source
❺ index the rank of the song into a dedicated field (with its stored value)
❻ index the title of the song into a dedicated field (with its stored value)
❼ index the artist who played the song into a dedicated field (with its stored value)
❽ index the song lyrics into a dedicated field (with its stored value)
❾ add the created Lucene document to the index
❿ persist the index into the file system
We can use the indexed data to build a char LSTM based Lookup implementation, called CharLSTMNeuralLookup. Similar to what we’ve been doing for the FreeTextSuggester, we can use a DocumentDictionary to feed the CharLSTMNeuralLookup.
Dictionary dictionary = new DocumentDictionary(reader, "lyrics", null); ❶
Lookup lookup = new CharLSTMNeuralLookup(...); ❷
lookup.build(dictionary); ❸❶ create a DocumentDictionary whose content is fetched from the indexed song lyrics
❷ create the Lookup based on the charLSTM
❸ train the charLSTM based Lookup
The DocumentDictionary will fetch the text from the field lyrics. In order to instantiate the CharLSTMNeuralLookup we need to pass the network configuration as a constructor parameter so that:
- at build time the LSTM will iterate over the characters of Lucene document values and learn to generate similar sequences
- at runtime the LSTM will generate characters based on the portion of the query already written by the user
Expanding the code listing above, the CharLSTMNeuralLookup constructor requires the parameters for building and training the LSTM.
int lstmLayerSize = 120;
int miniBatchSize = 40;
int exampleLength = 1000;
int tbpttLength = 50;
int numEpochs = 1;
int noOfHiddenLayers = 1;
double learningRate = 0.1;
WeightInit weightInit = WeightInit.XAVIER;
Updater updater = Updater.RMSPROP;
Activation activation = Activation.TANH; Lookup lookup = new CharLSTMNeuralLookup(lstmLayerSize, miniBatchSize, exampleLength, tbpttLength,
numEpochs, noOfHiddenLayers, learningRate, weightInit, updater, activation);
The implementation of the neural language model is very similar to something that one might use for an alternative query generation use case. The basic configuration of the 1 hidden layer LSTM is defined above and we use the same sampling code to pass typed query to the network and get the network output with its probability.
INDArray output = network.rnnTimeStep(input); ❶
int sampledCharacterIdx = sampleFromDistribution(output); ❷
char c = characterIterator.convertIndexToCharacter(sampledCharacterIdx); ❸❶ predict probability distribution over the given input character (vector)
❷ sample a probable character from the generated distribution
❸ convert the index of the sampled character to an actual character
We can therefore implement the Lookup#lookup API with our neural language model like this:
@Override
public List<LookupResult> lookup(CharSequence key, boolean onlyMorePopular, int num) throws IOException {
List<LookupResult> results = new LinkedList<>(); ❶
Map<String, Double> output = NeuralNetworksUtils.sampleFromNetwork(network,
characterIterator, key.toString(), num); ❷
for (Map.Entry<String, Double> entry : output.entrySet()) {
results.add(new LookupResult(entry.getKey(), entry.getValue().longValue())); ❸
}
return results;
}❶ prepare the list of results
❷ sample num sequences from the network, given the CharSequence (key parameter) entered by the user
❸ add the sampled outputs to the list of results, using their probabilities (from the SoftMax function) as suggestion weights
The CharLSTMNeuralLookup also needs to implement the build API. Since the CharacterIterator implementation relies on text coming from a file, we can create a temporary file to store the values:
@Override
public void build(InputIterator inputIterator) throws IOException {
Path tempFile = Files.createTempFile("chars",".txt"); ❶
FileOutputStream outputStream = new
FileOutputStream(tempFile.toFile());
for (BytesRef surfaceForm; (surfaceForm = inputIterator.next()) != null;) { ❷
outputStream.write(surfaceForm.bytes); ❸
}
outputStream.flush();
outputStream.close(); ❹
characterIterator = new CharacterIterator(tempFile.toAbsolutePath().toString(), miniBatchSize, exampleLength); ❺
this.network = NeuralNetworksUtils.trainLSTM(lstmLayerSize, tbpttLength, numEpochs, noOfHiddenLayers, ...); ❻
FileUtils.forceDeleteOnExit(tempFile.toFile()); ❼
}❶ create a temporary file
❷ fetch text coming from the lyrics field from the Lucene index (Lucene uses BytesRef instead of String for performance reasons)
❸ write the text into the temporary file
❹ release resources for writing into the temporary file
❺ create a CharacterIterator (using the CharLSTMNeuralLookup configuration parameters)
❻ build and train the LSTM (using the CharLSTMNeuralLookup configuration parameters)
❼ remove the temporary file
Before going forward and using this Lookup in our search application, we need to make sure that the neural language model works well and gives good results; like most of other algorithms in computer science, neural networks aren’t just “magic,” we need to set them up correctly if we want them to work nicely.
Tuning the LSTM language model
Instead of simply adding more layers to the network, we’ll start with a single layer and see if we can make it with that alone, by adjusting other parameters. The most important reason for this is that as the complexity of the network grows (e.g. more layers) the data and time required for the training phase to generate a good model (which gives good results) grows as well. So while we know that small shallow networks can’t beat deeper ones with lots of different data, this language modelling example is a good place to learn to start simple and go deeper only when needed.
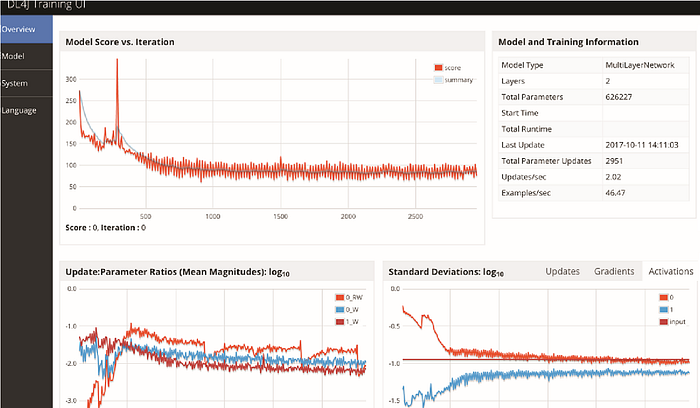
As you do more work with neural networks you’ll get to know how to best set and tune them. For now, we know that when data is large and diverse it might be a good idea to have a deep RNN for language modelling. But let’s be pragmatic and see if that’s true. In order to do that we need a way to evaluate the NN learning process. Neural network training is an optimization problem, where we want to optimize the weights in the connections between the neurons in order to let them generate the results we desire. This, in practice, means that we have an initial set of weights in each layer. These weights get adjusted during training so that the error the network commits when trying to predict outputs continually reduces as training goes on. If we see that the error committed by the network doesn’t go down or goes up, we have done something wrong in our setup. As you might be aware, cost functions measure such error and the objective of our neural network training algorithm is to minimize the cost function. A good way to start measuring if the training is doing well is to plot the cost (or loss) and makes sure it keeps going down as backpropagation proceeds.
Figure 7 is an example of how a server visualizes the aforementioned learning process:
And that’s where we’ll stop for now.
If you want to know more, check out the book on liveBook here and see this slide deck.
About the author:
Tommaso Teofili is a software engineer at Adobe Systems with a passion for open source and artificial intelligence. He is a long-time member of the Apache Software Foundation, where he contributes to many projects on topics like information retrieval, natural language processing, and distributed computing.
Originally published at freecontent.manning.com.
