ARTICLE
Forecasting Churn Risk with Machine Learning, Part 1
From Fighting Churn with Data by Carl Gold
This article discusses using machine learning algorithms to forecast churn risks.
_____________________________________________________________
Take 37% off Fighting Churn with Data by entering fccgold into the discount code box at checkout at manning.com.
_____________________________________________________________
Forecasting churn risk with machine learning
You can forecast churn with a regression in which predictions are made by multiplying metrics by a set of weights. You can also predict churn with other kinds of forecasting models which are collectively known as machine learning. |No official definition of what constitutes a machine learning model exists, but for the purpose of this article, I use the following:
DEFINITION A machine learning model is any predictive algorithm which has the following two characteristics: 1) the algorithm learns to make the prediction by processing sample data (as compared with making predictions with rules set by a human programmer), and 2) the algorithm isn’t the regression algorithm.
The second condition can seem strange because the regression algorithm certainly meets the first condition. This is really a historical distinction because the regression approach predates machine learning methods by decades.
The XGBoost learning model
This book covers only one machine learning algorithm named XGBoost, but the same techniques for fitting the model and forecasting apply to most other algorithms you may consider. The XGBoost algorithm is based on the concept of a decision tree, illustrated in figure 1.

DEFINITION A decision tree is an algorithm for predicting an outcome (such as a customer churning or not churning) that consists of a binary tree made up of rules or tests.
Each test in a decision tree takes a single metric and checks whether it is greater than or less than a predetermined cut point. The prediction for an observation (of a customer) is determined by starting at the root of the tree and performing the first test. The result of the test determines which of the two branches to follow from the node leading to one of the second level tests. The result of all the tests determines a path through the tree, and the leaves of the tree each has a designated prediction.
Small decision trees seem simple, and they used to be seen as an easy-to-interpret machine learning model. But in practice, large decision trees for datasets with many metrics become hard to interpret. Fortunately, no one has to read the rules in the tree to make a prediction.
An algorithm is used to test metrics and decide on the cut points to optimize performance when making predictions using the sample data. If a backtest shows the results are accurate, you can make predictions using a decision tree without being too concerned about the substance of the rules, but there are methods to interpret a decision tree. If you have more than a few metrics, then understanding the influence of metrics on the likelihood of churn is more easily done through grouping and regression methods, but I won’t spend time on interpreting decision trees.
Apart from being difficult to interpret, decision trees are no longer state-of-the-art in terms of prediction accuracy. But decision trees are the building blocks for more accurate machine learning models. One example of a more accurate machine learning model is a random forest, illustrated in figure 2.
DEFINITION A random forest is an algorithm for predicting an outcome such as a customer churning by randomly generating a large set of decision trees (a “forest”). All the trees try to predict the same outcome, but each does this according to a different set of learned rules. The final prediction is made by averaging the predictions of the forest.
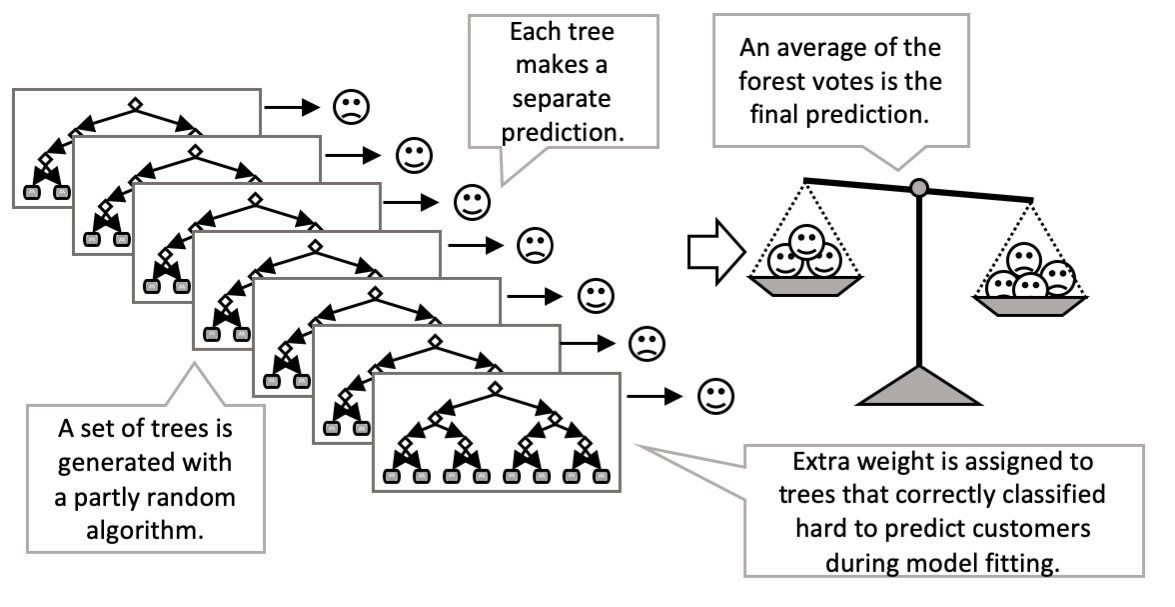
The random forest is an example of what’s called an ensemble prediction algorithm because the final prediction is made from the combination of a group of other machine-predicting algorithms. Ensemble means a group evaluated as a whole rather than individually. A random forest is a simple type of ensemble in that each tree gets an equal vote in the outcome, and additional trees are added at random. Boosting is a name for machine learning algorithms that make some important improvements over ensembles like random forest.
DEFINITION Boosting is a machine learning ensemble in which the ensemble members are added to correct the errors of the existing ensemble.
Rather than randomly adding decision trees like in a random forest, each new tree in a boosting ensemble is created to correct wrong answers made by the existing ensemble, rather than re-predict on the already correct examples. Internal to the boosting algorithm, successive trees are generated on subsamples of the data that over-emphasize the observations that were incorrectly classified by earlier trees. Also, the weight assigned to successive trees in the vote is related to how much they contribute to reducing the mistakes. These improvements make boosted forests of decisions trees more accurate than a truly random forest of decision trees.
XGBoost is short for extreme gradient boosting, and it’s the name for a machine learning model which (at the time of this writing) is the most popular and successful model for general-purpose prediction. XGBoost is popular because it delivers state-of-the-art performance, and the algorithm to fit the model is relatively fast (compared to other boosting algorithms, but as you’ll see, it isn’t fast compared to regression). Details about the XGBoost algorithm are beyond the scope of this article, but there are many excellent free resources online. For example, see https://en.wikipedia.org/wiki/XGBoost and https://en.wikipedia.org/wiki/Gradient_boosting.
XGBoost cross-validation
Machine learning algorithms like XGBoost can be accurate at predictions, but this accuracy comes with some additional complexity. One area of complexity is that the algorithms have multiple optional parameters that you must choose correctly in order to get the best results. The optional parameters for XGBoost include ones that control how the individual decision trees are generated, as well as parameters for how the votes of the different decision trees are combined. Here are a few of the most important parameters for XGBoost:
max_depth—The maximum depth of rules in each decision treen_estimator—The number of decision trees to generatelearning_rate—How heavily to emphasize the weight of votes from the best treesmin_child_weight—The minimum weight of each tree in the vote, regardless to how well it did
Because there’s no straightforward way to select the values for many parameters, they’re set by out-of-sample cross-validation, like you used for the control parameter on the regression.
TAKEAWAY State-of-the-art machine learning models have numerous parameters and the only way to make sure you pick the best values is to cross-validate a large number of them.
You test a sequence of plausible values for each parameter and choose the ones with the best values on a cross-validation test. Figure 3 shows an example of such a cross-validation result.
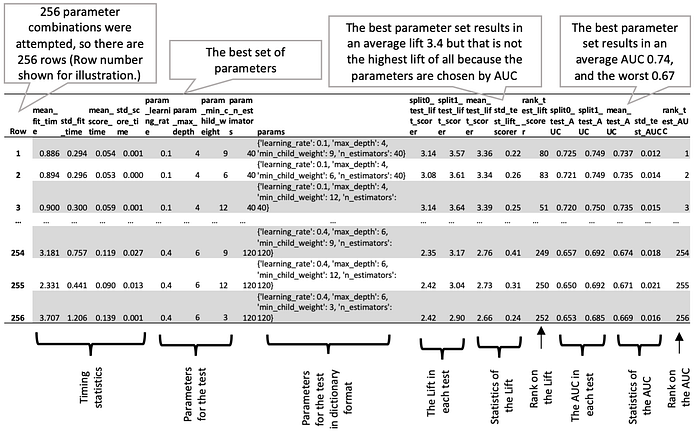
Figure 3 was created by running listing 1 on a simulated social network dataset.
- Four columns of parameters are there because four parameters were part of the test:
max_depth,n_estimator,learning_rate, andminimum_child_date. - It has many more rows in the output table: 256 parameter combinations to be precise. The reason there are 256 parameter combinations is clear when inspecting listing 9.6: the test is made over four parameters, and the sequence of values for each parameter has four entries. The total number of combinations is the product of the number of values for each parameter; in this case, 4 x 4 x 4 x 4 = 256.
You should run listing 1 on your own simulated data using the following usual Python wrapper program command with these arguments:
fight-churn/listings/run_churn_listing.py --chapter 9 --listing 6Don’t be surprised if the cross-validation for the XGBoost model takes a lot longer than it did for the regression. Not only are there a lot more parameter combinations to test, but each time a model is fit, it takes significantly longer. The precise time can vary (depending on your hardware), but for me, the XGBoost model takes about forty times longer to fit in comparison with the regression model. The regression takes only a few hundredths of a second to fit on average; figure 3 shows that the XGBoost fits take from around one to four seconds.
NOTE XGBoost is in its own Python package, and if you haven’t used it before now, you need to install it before running listing 1.
Check out what this looks like in code in the continuation in Part 2.
That’s all for this article. If you want to learn more about the book, you can preview its contents on our browser-based liveBook platform here.
This article was originally posted here: https://freecontent.manning.com/forecasting-churn-risk-with-machine-learning-part-1/
