ARTICLE
Forecasting Churn Risk with Machine Learning, Part 2
From Fighting Churn with Data by Carl Gold
This article discusses using machine learning algorithms to forecast churn risks.
______________________________________________________________
Take 37% off Fighting Churn with Data by entering fccgold into the discount code box at checkout at manning.com.
______________________________________________________________
Continued from Part 1, in which the XGBoost machine learning model and how it can be used to predict churn is presented. Below, listing 1 shows XGBoost cross-validation for regression.
Listing 1. XGBoost cross-validation
import pandas as pd
import pickle
from sklearn.model_selection import GridSearchCV, TimeSeriesSplit
from sklearn.metrics import make_scorer
import xgboost as xgb #A
from listing_8_2_logistic_regression import prepare_data
from listing_9_2_top_decile_lift import calc_lift
def crossvalidate_xgb(data_set_path,n_test_split):
X,y = prepare_data(data_set_path,ext='',as_retention=False) #B
tscv = TimeSeriesSplit(n_splits=n_test_split)
score_models = {'lift': make_scorer(calc_lift, needs_proba=True), 'AUC': 'roc_auc'}
xgb_model = xgb.XGBClassifier(objective='binary:logistic') #C
test_params = { 'max_depth': [1,2,4,6], #D
'learning_rate': [0.1,0.2,0.3,0.4], #E
'n_estimators': [20,40,80,120], #F
'min_child_weight' : [3,6,9,12]} #G
gsearch = GridSearchCV(estimator=xgb_model,n_jobs=-1, scoring=score_models, #H
cv=tscv, verbose=1, return_train_score=False,
param_grid=test_params,refit='AUC') #I
gsearch.fit(X.values,y) #J
result_df = pd.DataFrame(gsearch.cv_results_) #K
result_df.sort_values('mean_test_AUC',ascending=False,inplace=True) #L
save_path = data_set_path.replace('.csv', '_crossval_xgb.csv')
result_df.to_csv(save_path, index=False)
print('Saved test scores to ' + save_path)
pickle_path = data_set_path.replace('.csv', '_xgb_model.pkl') #M
with open(pickle_path, 'wb') as fid:
pickle.dump(gsearch.best_estimator, fid) #N
print('Saved model pickle to ' + pickle_path)#A Imports XGBoost, which is in a separate package
#B Most of this function is the same as listing 9.5, the regression cross-validation.
#C Creates an XGBClassifier object for a binary outcome
#D Tests tree depths from 1 to 6
#E Tests learning rates from 0.1 to 0.4
#F Tests number of estimators from 20 to 120
#G Tests minimum weight from 3 to 12
#H Creates the GridSearchCV object with the XGBoost model object and tests parameters
#I Refits the best model according to AUC after cross-validation
#J Passes as values, not a DataFrame, to avoid a known package issue at the time of this writing
#K Transfers the results to a DataFrame
#L Sorts the result to get the best AUC first
#M Creates a pickle of the best result
#N The best result is in the best_estimator field of the GridSearchCV object.
The code in listing 1 is similar to what you would have for cross validating the regression. The main steps are
- Prepares the data
- Creates a model instance (in this case, an XGBoost model)
- Defines the accuracy measurement functions to use (lift and AUC)
- Defines the sequences of parameters to test
- Passes these in the
GridSearchCVobject and calls thefitfunction - Saves the results (with no additional analysis like in the regression cross validation).
One important and slightly subtle difference between listing 1 and regression cross-validation is that the dataset would be created from the original unscaled metrics, and it doesn’t use scores or groups like you would for the regression. Re-scaling the metrics for XGBoost (or decision trees, generally) is pointless because the cut points in the rules operate as well on the metrics regardless of scale or skew. And grouping correlated metrics doesn’t provide any benefit. In fact, it can hurt the performance of this type of machine learning model. Grouping correlated metrics is beneficial for interpretation and helps avoid the problems that correlated metrics can cause in regression.
On the other hand, for XGBoost, a diversity of metrics is beneficial and correlation does no harm. If two metrics are correlated, either one can make a suitable rule node in a tree. For these reasons, the prepare_data function is called with an empty extension argument, so that it loads the original dataset rather than loading the grouped scores (the default behavior).
Comparison of XGBoost accuracy to regression
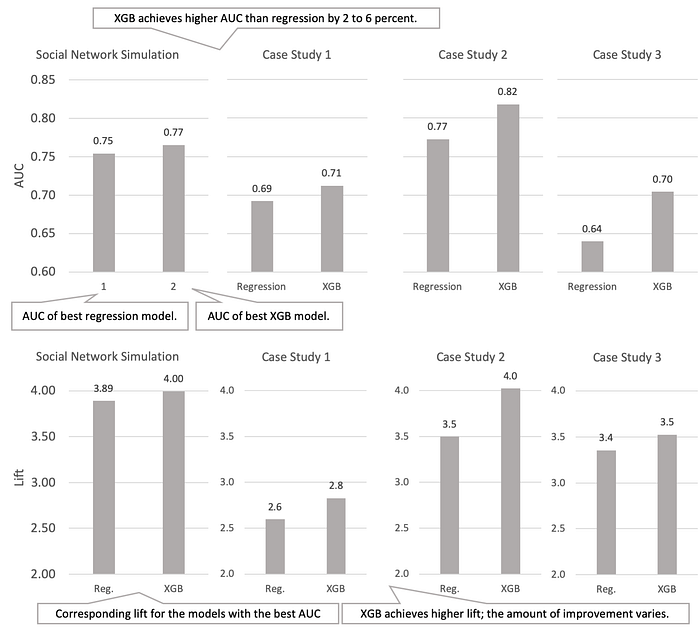
Because XGBoost takes much longer to fit the larger number of parameters, you should expect that it provides some improvement in the forecasting accuracy. This expectation is confirmed in figure 1, which compares the AUC and lift achieved by regression and XGBoost models for the simulation, as well as three real company case study datasets for the companies. The AUC improvement ranges from 0.02 to 0.06, and XGBoost always produces more accurate forecast than the regression. In terms of lift, the improvement is from 0.1 to 0.5.
Are those improvements significant? Remember that the full range of AUCs you’re likely to see in churn forecasting is from around 0.6 to 0.8. The maximum AUC, therefore, is 0.2 more than the minimum, and in relative terms, an improvement of 0.02 in AUC represents around a ten percent improvement in terms of the overall possible range. By the same token, a 0.05 improvement in AUC represents twenty-five percent of the difference between worst and best in class, and these really are significant improvements. Still, the forecasting isn’t perfect, even with machine learning. This is why I advise that predicting churn with machine learning isn’t likely to live up to some of the hype in the machine learning field.
TAKEAWAY Though machine learning algorithms can produce forecasts that are significantly more accurate than regression, churn is always hard to predict due to factors like subjectivity, imperfect information, rarity, and extraneous factors influencing the timing of churn.
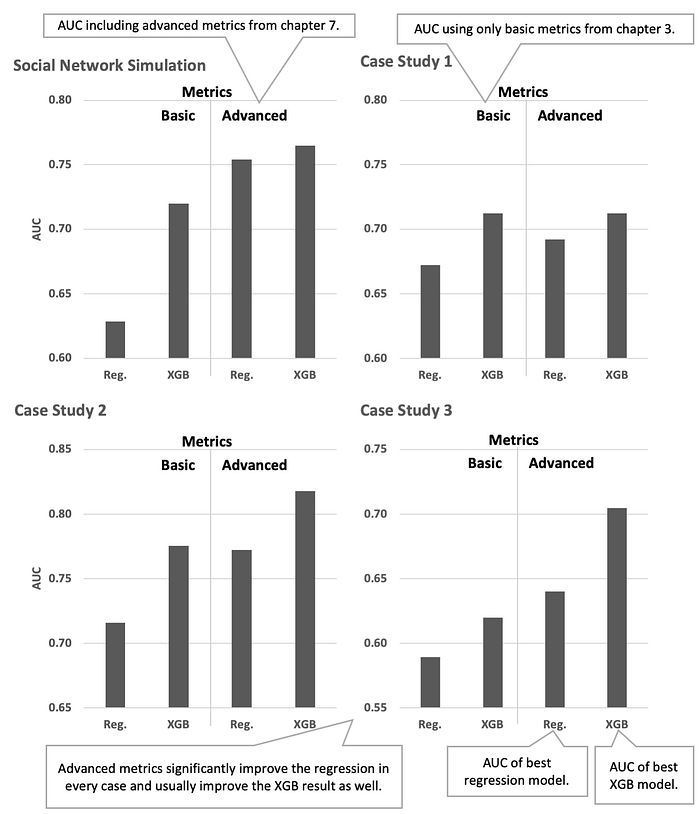
Comparison of advanced and basic metrics
Another important question that you might have been wondering is how much improvement in accuracy can be attributed to advanced metrics? The relationship to churn in cohort analysis must have improved the model, but like you want to validate your data and modeling by showing your model can predict out of sample, it also makes sense to confirm that the work you did creating more metrics contributed something empirically.
In order to make the comparison on the simulated social network datasets, there are additional versions of the cross-validation testing command which run on the original dataset. That is, you run the dataset without advanced metrics or the basic metrics. To run the regression cross-validation on the basic metric dataset, use the following:
fight-churn/listings/run_churn_listing.py --chapter 9 --listing 5 --version 1That produces a cross-validation table. You’ll probably find that the maximum accuracy of any model is somewhat less for the data with only basic metrics compared to the data with advanced metrics. As illustrated in the bar chart in figure 2, the maximum accuracy that I got on my regression simulation with only basic metrics was 0.63; for the regression on the simulated data with advanced metrics, the maximum AUC was 0.75: a 0.12 difference. The time spent creating advanced metrics was well spent. In fact, the regression accuracy with advanced metrics is significantly better than XGBoost with basic metrics, and the additional improvements from the machine learning algorithm are relatively small.
You can also perform the same check on the XGBoost model by running the second version of the XGBoost cross-validation command with these arguments:
fight-churn/listings/run_churn_listing.py --chapter 9 --listing 6 --version 1In this case, you’ll probably find that the XGBoost forecasts did a bit better with the advanced metrics. For my simulation, I got an AUC of 0.774 using the XGBoost with the basic metrics alone as compared with 0.797 for XGBoost with advanced metrics: the improvement attributable to advanced metrics is 0.023.
Figure 4 also contains similar comparisons for forecasts made on three real company case studies introduced. These each show different relationships between accuracy with and without the advanced metrics. These three cases illustrate the range of scenarios you can encounter on your own case studies:
- For the first case study, the regression accuracy is significantly improved by the advanced metrics, but the XGBoost doesn’t get any improvement, and XGBoost is best overall. This shows you can’t always expect advanced metrics to improve machine learning.
- For the second case study, both the regression and the XGBoost are significantly improved by the addition of advanced metrics. The regression accuracy with the advanced metrics is about the same as the XGBoost accuracy with only basic metrics. The XGBoost accuracy with advanced metrics is the highest of all by a significant amount: around 0.1 more than regression with basic metrics.
- For the third case study, the regression using advanced metrics has higher accuracy than XGBoost without advanced metrics. But the highest accuracy is achieved by XGBoost using advanced metrics: more than 0.1 improvement over the basic metrics and regression. This case study is most similar to the social network simulation.
These cases demonstrate that if high accuracy on churn forecasts is a high priority for you, then both machine learning and advanced metrics are important. In my experience, advanced metrics usually improve the accuracy of churn forecasts for both regression and machine learning models like XGBoost.
That’s all for this article. If you want to learn more about the book, you can preview its contents on our browser-based liveBook platform here.
This article was originally posted here: https://freecontent.manning.com/forecasting-churn-risk-with-machine-learning-part-2/
